
웹 스크래핑
이번 글에서는 웹 스크래핑에 대해서 알아볼 것입니다.
과거에는 원하는 정보를 수동으로 웹에서 복사하거나 이미지를 다운로드하는 것이 일반적이었지만, 수집하려는 데이터가 많아질수록 이런 작업은 비효율적이고 시간이 오래 걸립니다. 예를 들어, 수백 개의 뉴스 기사나 수천 장의 이미지를 수동으로 저장하려면 엄청난 시간이 필요합니다.
하지만 이제 누구나 코딩을 배울 수 있고, 누구나 파이썬을 할 수 있게 많은 자료가 있습니다. 그래서 파이썬의 라이브러리 중 하나인 BeautifulSoup를 이용해서 가져오고 싶은 데이터를 스크래핑을 해보려고 합니다.
BeautifulSoup
BeautifulSoup는 HTML 파일이나 XML 문서를 파싱해서 데이터를 추출하는 라이브러리입니다. 가볍고 빨라서 정적인 웹페이지의 HTML을 처리하기 좋습니다. 다만, 동적 웹페이지는 처리하지 못해서 동적 웹페이지에서는 BeautifulSoup가 아닌 Selenium을 사용하는데, 이번에는 BeautifulSoup를 사용할 예정입니다.
BeautifulSoup vs Selenium
특징 | BeautifulSoup | Selenium |
처리 대상 | 정적 웹페이지 (HTML/XML) | 동적 웹페이지 (자바스크립트) |
속도 | 빠름 | 느림 (실제 브라우저 실행) |
리소스 소비 | 낮음 | 높음 (브라우저 실행으로 인한 리소스 사용) |
사용 난이도 | 쉬움 | 다소 복잡함 |
웹 상호작용 | 불가 | 가능 (클릭, 입력, 스크롤 등) |
HTTP 요청 | Requests와 같은 추가 도구 필요 | 자체적으로 브라우저 내에서 처리 |
적합한 작업 | 대규모 데이터 수집, 빠른 스크래핑 작업 | 동적 콘텐츠 처리, 웹 테스트, 상호작용 작업 |
프로젝트
1. 준비
진행했던 프로젝트 중에 뉴스 기사를 토대로 주가의 방향을 예측하는 프로젝트가 있었는데, 그러기 위해서는 코스피 시총 상위 100개 기업에 대한 뉴스를 수집했어야 했습니다. 그래서 BeautifulSoup를 이용해서 네이버에 있는 기업 관련된 뉴스를 스크래핑을 하려고 합니다.
BeautifulSoup는 Selenium과는 다르게 별도의 브라우저 드라이브 설치 없이 라이브러리만 설치하면 바로 사용할 수 있습니다.
pip install beautifulsoup4
Python
복사
BeautifulSoup를 설치하고, 요구사항에 맞게 실제 데이터를 스크래핑 시작하겠습니다.
2. 코스피 시가총액 상위 100개 기업 리스트 가져오기
먼저 수집해야 할 코스피 상위 100개 기업의 리스트를 가져오려고 합니다. 한국거래소에서 각 기간별 코스피 기업을 확인할 수 있고, 그곳에서 csv로 데이터를 이미 추출한 상황입니다. 그래서 아래 코드를 토대로 실제 코스피 기업 목록 100개를 가져와봅시다.
import pandas as pd
company = pd.read_csv('./raw/19년 1월 2일 기준(코스피).csv',encoding='utf-8')
company_list = company.iloc[:100,]['종목명'][0:100] # 시총 상위 100개 기업 리스트
Python
복사
3. 네이버 뉴스 검색 URL 분석
BeautifulSoup를 이용하여 웹 스크래핑을 해야 하는데, 특정 회사에 대한 뉴스를 특정 기간에 맞춰서 가져와야 되므로, 이용할 url에서 규칙을 찾아야 합니다.
예를 들어서, 네이버에서 삼성전자를 검색한 후 뉴스 탭에 들어가서 기간을 설정하면 다음과 같은 url을 얻을 수 있습니다.
ds(date_start)와 de(date_end)를 통해서 검색할 기간을 설정할 수 있기 때문에, ds, de 타입에 맞는 수집 기간을 아래 코드를 토대로 리스트로 만들어봅시다.
import datetime
days_list=[]
# datetime.datetime(yyyy,m,d,0,0)
start = datetime.datetime.strptime("2019-01-01", "%Y-%m-%d")
end = datetime.datetime.strptime("2020-01-01", "%Y-%m-%d") # 원하는 날짜 + 1 입력
# 수집을 원하는 기간을 list로 만들어준다. // datetime.datetime(yyyy,m,d,0,0)으로 저장
date_list = [start + datetime.timedelta(x) for x in range(0, (end-start).days)]
for date in date_list:
#datetime 형식을 str로 만들어 days_list에 삽입 // yyyy.mm.dd로 저장
days_list.append(date.strftime("%Y-%m-%d").replace('-','.'))
Python
복사
그리고 네이버 검색에서는 뉴스가 한 페이지에 최대 10개씩 노출되는데, 그래서 다음 페이지를 누르면 url에 &start=11이 추가되는 것을 확인할 수 있습니다.
그래서 url에서 컨트롤할 수 있는 부분을 정리하면 아래와 같습니다.
1.
where=news&query=기업명
a.
뉴스 항목에서 기업명으로 검색하기
2.
ds=2019.01.01&de=2019.12.31
a.
date_start와 date_end를 통해서 조회할 기간 설정하기
3.
&start=11
a.
각 조회마다 최대 10개의 결과를 가져옴
b.
최대 조회 가능한 기사의 개수는 4000개로 제한
i.
ds와 de 옵션을 사용할 때만 적용
4. 네이버 뉴스 html 분석
이제는 수집할 기사들을 들어가보면서 네이버 뉴스의 형식이 어떻게 되어있는지 개발자 도구(F12)를 통해서 알아보려고 합니다.
1.
뉴스 타이틀은 아래와 같이 h3에 들어가 있습니다.
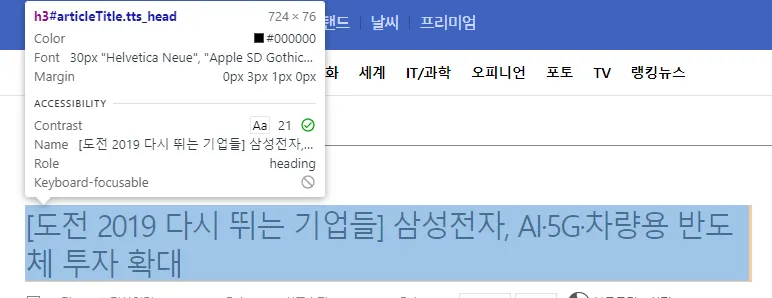
2.
뉴스 본문은 아래와 같이 div의 _article_body_contents라는 클래스로 들어있습니다.
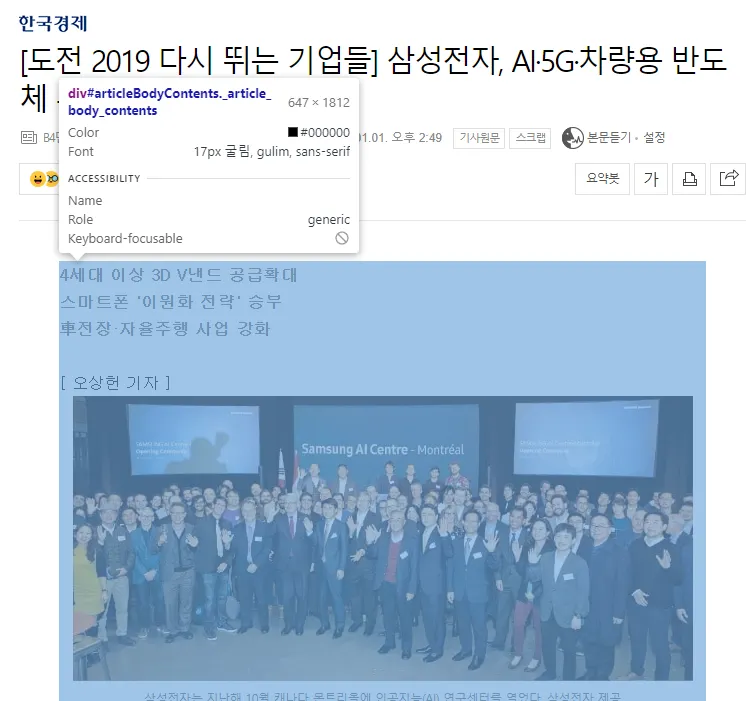
5. BeautifulSoup로 원하는 데이터 가져오기
위에서 어떤 방식으로 검색 방법을 바꿔서 가져올지, 어디서 어떤 데이터를 가져올지 정했습니다.
그래서 우리는 2019년도의 모든 뉴스 데이터에서 코스피 상위 100개 기업에 해당하는 기업명을 검색해서, 뉴스의 타이틀과 본문 데이터를 가져오려고 합니다.
import timeit
import requests
import re
import bs4
# user-agent를 이용하여 비정상적인 접근으로 인한 차단 방지
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
for company in company_list:
df_news = pd.DataFrame(columns=['ID','Day','Head','Main']) # 각 회사별 데이터프레임 초기화
count = 0 #데이터프레임 인덱스
start_time = timeit.default_timer() # 시작 시간 체크
print(company)
for day in days_list:
print('-----------'+day+'-----------') # 크롤링 과정 중 어디 기간을 수집하는지 확인하기 위해서
# ds와 de를 길게 설정하면 4000개 제한으로 모든 기사를 가져오지 못하므로 하루씩 조회해서 가져온다.
url = 'https://search.naver.com/search.naver?where=news&query='+company+'&pd=3&ds='+ day +'&de='+ day + '&start='
link_list = [] # 먼저 네이버뉴스로 확인 가능한 기사만 링크 리스트에 저장
for page in range(0, 400): #네이버 뉴스 최대 조회수가 4000개에 맞게끔 범위 지정
start = page*10+1 #네이버 뉴스는 한페이지에 최대 10개씩 노출
new_url = url + str(start)
res = requests.get(new_url)
bs_obj = bs4.BeautifulSoup(res.text, 'lxml')
list_info = bs_obj.find_all('a', {'class': re.compile('info$')}) #네이버뉴스가 있는 클래스명이 'info'
temp_info = bs_obj.find_all('a', {'class': re.compile('news_tit')}) #뉴스 타이틀
for i in list_info:
if i.get_text() == '네이버뉴스':
c = i.get('href')
if c.find('sports') != -1: # 주식과 관련없는 스포츠에 해당되는 뉴스 삭제(실제 스포츠뉴스는 기존 뉴스와 양식도 다름)
continue
if c not in link_list: # 중복되는 기사가 있으므로 확인 후 리스트에 삽입
link_list.append(c)
if len(temp_info) < 10: #링크 크롤링시 종료 조건 설정을 뉴스 타이틀 갯수로 판단
break
for link in link_list: #링크 뽑은 후 기사 크롤링 시작
try: #간혹 링크에 따라 들어가더라도 네이버뉴스 창이 아닌 다른 창이 뜨는 경우 발생하여 예외처리 필요
res = requests.get(link, headers=headers) #네이버 뉴스는 헤더없이 접근시 접근 불가
bs_obj = bs4.BeautifulSoup(res.text, 'lxml')
a = link.find('sid1')
b = link.find('oid')
c = link.find('aid')
news_id = link[a+5:a+8]+link[b+4:b+7]+link[c+4:c+14] #고유ID 생성
day_span = bs_obj.find('span', {'class':'t11'}) # 뉴스 날짜
if day_span != None:
day_info = day_span.text
else:
day_info = None
head_info = bs_obj.find('h3').text # 뉴스 타이틀
main_info = bs_obj.find('div', {'class':'_article_body_contents'}).text.replace("// flash 오류를 우회하기 위한 함수 추가\nfunction _flash_removeCallback() {}","") # 뉴스 본문
except AttributeError as e: #예외 처리시 널값을 넣어서 진행은 하되 추후에 제거 가능하도록 지정
news_id = head_info = main_info = None
day_info='0000000000'
df_news.loc[count] = [news_id,day_info[0:10],head_info,main_info] #데이터프레임 삽입
count += 1
terminate_time = timeit.default_timer() # 종료 시간 체크
print("%s : %f초" % (company,terminate_time - start_time))
df_news.to_csv("./raw/기사/%s.csv" %(company), mode='w',encoding = 'utf-8-sig') # 각 회사별로 파일 생성
Python
복사
6. 마무리
위의 코드를 실행하여 우리는 코스피 상위 100개 기업의 2019년 한 해 동안의 뉴스 기사를 수집했습니다.
BeautifulSoup는 Selenium보다 빠른데도, 웹 스크래핑하는데 많은 시간(6시간 이상)이 걸렸습니다.
그리고 수백만개의 기사에서 타이틀과 본문, 딱 2가지만 수집하였음에도 약 3.5GB에 해당하는 데이터를 수집하였습니다.
다음 글에서는 해당 기사들을 가져와서 전처리를 진행하여 기계학습을 시키기 위한 데이터로 만들어보겠습니다.