
주가 예측
이번 글에서는 뉴스 기사로 주가의 방향을 예측하는 머신러닝 모델을 방법에 대해서 알아볼 것입니다.
미래에 오를 주식을 미리 아는 것을 누구나 한번은 상상해 본 적이 있을 겁니다. 아니면 현재의 기억을 가지고 가거나 돌아간다면 미래의 가치가 오를 것들에 대해서 미리 투자할 수도 있습니다. 이와 같이 미래에 일어날 일에 대해서 예측하여 돈을 벌고자 하는 행동은 수많은 사람들의 관심을 받아 왔고, 주가를 예측하는 것 또한 마찬가지입니다.
주가를 예측하는 것은 예전부터 계속해서 시도되어 왔고, 지금도 계속해서 연구 중인 분야인데, 주가에 영향을 끼치는 요소는 매우 다양하고, 이에 따라서 분석하기 위해 접근하는 방법도 매우 다양합니다. 다양한 주식 지표로 접근하는 방법부터 차트의 모양새를 보고 판단하거나, 재무제표를 토대로 회사의 방향을 예측하는 등 다양한 방법들이 있습니다.
이러한 것들을 토대로 머신러닝과 딥러닝을 도입하여 실제 주가를 예측하고자 하는 시도도 많이 있었는데, 이번에 진행할 프로젝트에서는 일반적으로 사용하는 차트와 주식 지표로 접근하는 것이 아니라 주식에 대한 정보를 잘 모르는 개미투자자로서 주식에 대해 접근해 보려고 합니다.
뉴스를 통한 주가 상승·하락 예측
일반적으로 특정 기업에 대해서 정보를 어디서 얻을 수 있겠느냐고 생각하면 해당 기업에서 내는 공시도 있지만, 개미투자자가 관심이 있는 기업에 대한 공시를 확인하기는 어려울 것이고, 그 공시를 확인할 수 있는 주기 또한 일정하지 않습니다.
하지만 우리는 특정 기업에 대해서 검색을 해보면 그 기업에 대한 기사가 엄청나게 쏟아지는 시대에 살고 있고, 그 기사에는 무조건적인 신뢰를 할 수는 없지만 우리는 그 기업에 대한 다양한 정보를 얻을 수 있습니다.
그리고 이전 날의 기사에서 좋은 소식이 포함된 뉴스가 많으면 그 다음 날 가격에 좋은 영향을 끼칠 것이고, 나쁜 소식이 포함된 뉴스가 많으면 그 다음 날 가격에 악영향을 끼칠 것이라고 생각했습니다.
그래서 기업별로 산업 분야에 따라 호재와 악재라고 인식되는 사건들이 있을 것이고, 이런 것들이 뉴스에서 주가에 좋은 영향을 끼치는 키워드와 나쁜 영향을 끼치는 키워드로 나눌 수 있다고 생각하였습니다.
그래서 수집한 기사들을 자연어 처리를 통해서 날짜별로 그날의 핵심 키워드들에 점수를 주는 방식으로 데이터를 만들어서, 이 데이터를 토대로 다음 날의 주가가 상승할지 하락할지 예측하려고 합니다.
일반적으로 주가 예측 프로젝트는 주식별로 시계열 데이터를 이용하여 분석하는 경우가 많은데, 이번 프로젝트에서는 시계열이 아닌 전날 기사들을 통해서 다음날 주가가 상승할지 하락할지를 예측하는 분류모델을 만들어보려고 합니다.
프로젝트
1. 데이터 전처리
일단 위의 과정을 통해서 단순하게 2019년 기준 코스피 시총 상위 100개 기업에 대해서 1년 치의 뉴스 기사를 수집할 수 있었습니다. 이 과정을 통해서 단순하게 기사의 제목과 본문을 가져온 것이기 때문에, 그 기사들의 제목과 본문 내용을 간단하게 전처리할 필요가 있습니다.
여기서 전처리 과정은 크게 2가지로 진행하였습니다.
1-1. 정규 표현식
첫 번째는 정규 표현식을 이용하여 한글을 제외한 다른 문자와 특수 문자들을 제거하는 것입니다.
정규표현식은 문자열에서 패턴을 찾거나 특정 형식에 맞는 데이터를 효율적으로 추출·변환하기 위해 사용됩니다. 이를 통해 불필요한 문자 제거, 특정 형식의 데이터 추출(예: 이메일, 날짜) 등을 쉽게 처리할 수 있습니다. 문자열 전처리 과정에서 데이터 정리와 형식 통일을 빠르고 간결하게 할 수 있도록 도와줍니다.
그래서 아래 코드를 통해서 뉴스 기사에서 한글과 띄쓰기를 제외한 모든 문자를 제거하려고 합니다.
import pandas as pd
import re
import timeit
company = pd.read_csv('./raw/19년 1월 2일 기준(코스피).csv',encoding='utf-8')
company_list = company.iloc[:100,]['종목명'][0:100] # 시총 상위 100개 기업 리스트
for company in company_list:
start_time = timeit.default_timer() # 시작 시간 체크
df = pd.read_csv("./raw/기사/%s.csv" %(company))
df_del = df[df['Day']=='0000000000'].index # 이전 뉴스 스크래핑 당시에 형식에 맞지 않은 기사는 00000000을 넣어주어서 결측치 처리
df1 = df.drop(df_del)
# 형태소 처리 전단계까지 전처리한 Head, Main 컬럼
data_head = []
data_main = []
data_day = []
data_id = []
for idx, val in df1.iterrows():
# 한글, 띄어쓰기 제외한 모든 문자 제거
parse = re.compile('[^ ㄱ-ㅣ가-힣+]') # 간단한 정규표현식
if val['Main'] == None or val['Head'] == None or val['Day'] == '0000000000':
continue
result_main = parse.sub('', str(val['Main']))
result_head = parse.sub('', str(val['Head']))
result_day = str(val['Day'])
result_id = str(val['ID'])
data_head.append(result_head)
data_main.append(result_main)
data_day.append(result_day)
data_id.append(result_id)
col_name1 = ['Head_after']
trans_head = pd.DataFrame(data_head, columns=col_name1)
col_name2 = ['Main_after']
trans_main = pd.DataFrame(data_main, columns=col_name2)
col_name3 = ['Day']
trans_day = pd.DataFrame(data_day, columns=col_name3)
col_name4 = ['ID']
trans_id = pd.DataFrame(data_id, columns=col_name4)
df3 = pd.concat([trans_id,trans_day, trans_head, trans_main], axis = 1)
df3.to_csv("./전처리/1차 전처리 기사/%s_전처리.csv" %(company), mode='w',encoding = 'utf-8-sig')
terminate_time = timeit.default_timer() # 종료 시간 체크
print("%s : %f초" % (company,terminate_time - start_time))
Python
복사
1-2. 형태소 분석기
두 번째는 형태소 분석기를 이용해서 한국어 자연어 처리를 진행하여 명사만 뽑아내고, 불용어 사전을 이용하여 기계학습에 필요 없는 단어를 추가로 제거하는 과정입니다.
형태소 분석기는 문장을 구성하는 단어를 가장 작은 의미 단위인 형태소로 분해하고, 각 형태소의 품사 정보를 파악하기 위해 사용됩니다. 이를 통해 자연어 처리 과정에서 단어의 의미를 더 정확하게 이해하고 분석할 수 있습니다. 주로 텍스트에서 단어를 추출하거나, 문법적 역할을 분석하는 데 활용됩니다.
영어 같은 경우는 띄어쓰기를 토대로 단어들을 토큰화하기 쉽지만, 한국어의 경우, 다양한 어미와 조사들이 있기 때문에 단순하게 토큰화하기 어렵습니다. 그래서 한국어 자연어 처리 라이브러리인 KoNLPy에는 다양한 형태소 분석기를 비교하여, 현재 프로젝트에 필요한 형태소 분석기를 사용하려고 합니다.
1-3 .형태소 분석기별 비교
한국어 자연어 처리 라이브러리인 KoNLPy의 공식 문서를 보더라도 형태소 분석기별 차이가 나와 있는데, 소요 시간에 대한 부분은 mecab이 압도적으로 빠른 것을 확인할 수 있습니다.
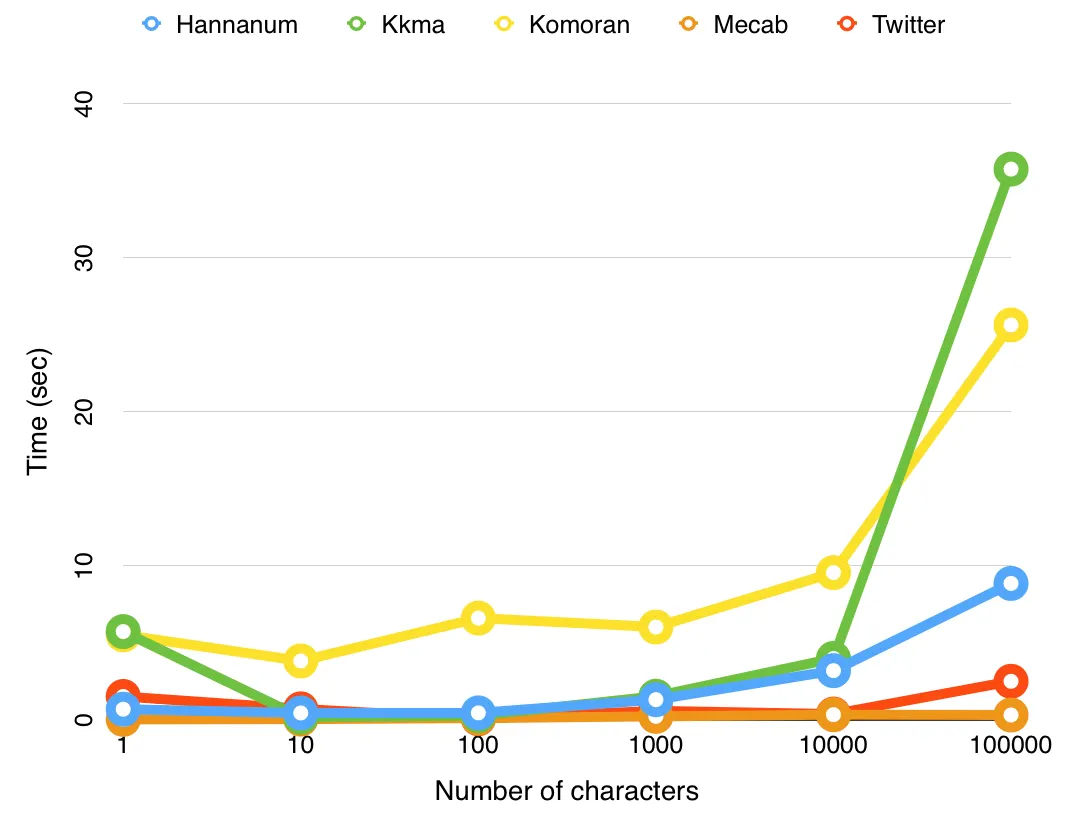
그래서 이번 프로젝트에서 사용할 데이터를 이용하여 각 형태소 분석기별로 실제 작업에 걸린 시간을 비교해 보았습니다.
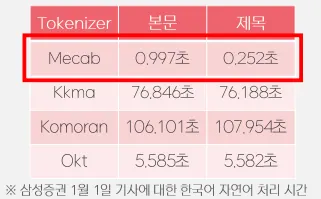
이 프로젝트에서 다룰 총 기사의 양이 수백만 개나 되는데, (텍스트로만 약 3.5GB) 삼성증권 기업의 하루치 기사를 작업하는데도 각 형태소 분석기별로 상당한 차이를 알 수 있었습니다. 그래서 최대한 많은 양의 기사를 작업하기 위해서 은전한닢에서 제공하는 mecab이라는 형태소 분석기를 사용하였습니다.
1-4. 명사만 가져오기
각 기사에서 반복적으로 나오는 단어가 필요하므로 형태소 분석기를 이용하여 명사만 가져오도록 하였습니다. mecab을 설치 후 불러와서 nouns(명사 추출) 함수를 불러와서 input으로 문자열을 넣어주면 됩니다. 그러면 나온 단어들을 리스트로 반환해 줍니다.
from eunjeon import Mecab
main = df_total['Main_after']
for i, news in enumerate(main):
nouns_list = mecab.nouns('%s' %news)
Python
복사
1-5. 불용어 사전
하지만 뉴스 기사 특성상 기사나 기자와 같이 분석에는 의미 없지만 반복적으로 나타나는 단어들이 많이 있으니, 이런 단어들을 없애주는 과정이 추가로 필요합니다. 그래서 불용어 사전을 추가로 만들어서 작업을 진행하였습다.
그리고 추가적으로 pickle을 통해서 불용어 사전을 저장해두고, 추후에 필요할 때마다 업데이트를 하거나 불러와서 사용을 하면 됩니다.
import pickle
stopwords = '''
이곳에
불용어로
만들고
싶은
단어들을
넣자
'''.split('\n')
with open('word_dict.pkl','wb') as f:
pickle.dump(stopwords,f)
Python
복사
1-6. 최종 전처리
최종적으로 진행된 전처리는 아래와 같습니다.
(추가로 단어의 길이가 한 개인 것도 큰 의미를 가지기 힘들어서 len(word)<2라는 조건문을 사용하여 제거하였습니다)
100개 기업에 대해서 수백만 개의 기사들이 아래와 같은 과정을 거쳐서, 기업별로 365일에 해당하는 365개의 문자열을 만들어주었습니다. 이론상으로 365 * 100을 하여 36500개의 row가 total_df에 저장되어야 하지만, 기사가 없는 날도 있으므로, 총 32500개의 row가 생성되었습니다.
import pandas as pd
import numpy as np
import re
import timeit
import pickle
from eunjeon import Mecab
mecab = Mecab()
with open('word_dict.pkl','rb') as f:
stopwords = pickle.load(f)
company = pd.read_csv('./raw/19년 1월 2일 기준(코스피).csv',encoding='utf-8')
company_list = company.iloc[:100,]['종목명'][0:100]# 시총 상위 100개 기업 리스트
total_df = pd.DataFrame(columns=['Company','Day','Main','Head'])
# 분석 중에 불용어 사전에 추가하고 업로드하기 힘들 경우, 아래와 같이 리스트를 추가해서 사용
list_del= ['기사','기자','신문','네이버','뉴스','연합뉴스','하이닉스','텔레콤','사진','데일리','가운데','구독',\
'이날','이후','지난해','최근','삼성','종목','한국','거래소','현대','종합','주요'] + company_list.to_list()
stopwords += list_del
for company in company_list:
df = pd.read_csv("./전처리/1차 전처리 기사/%s_전처리.csv" %(company),encoding='utf-8')
df.dropna(axis=0,inplace=True)
df['Day']=df['Day'].str[:10]
df_head = df.groupby(['Day'])['Head_after'].apply(' '.join).reset_index()
df_main = df.groupby(['Day'])['Main_after'].apply(' '.join).reset_index()
df_total = pd.merge(df_head,df_main,on='Day')
temp_pd = pd.DataFrame()
print("------"+ company +"------")
start_time = timeit.default_timer()
main = df_total['Main_after']
temp_list_main = []
for i, news in enumerate(main):
nouns_list = mecab.nouns('%s' %news) # mecab에서 nouns라는 명사 추출하는 함수 사용
clean_words = []
for word in nouns_list:
if len(word) < 2: # 단어가 한글자인 경우 생략
continue
if word not in stopwords: # 단어가 불용어 사전에 없을 경우만 리스트에 삽입
clean_words.append(word)
total_nouns = ' '.join(clean_words)
temp_list_main.append(total_nouns)
terminate_time = timeit.default_timer()
print("Main 처리 시간 : %f초" % (terminate_time - start_time))
start_time = timeit.default_timer()
head = df_total['Head_after']
temp_list_head = []
for i, news in enumerate(head):
nouns_list = mecab.nouns('%s' %news)
clean_words = []
for word in nouns_list:
if len(word) < 2:
continue
if word not in stopwords:
clean_words.append(word)
total_nouns = ' '.join(clean_words)
temp_list_head.append(total_nouns)
terminate_time = timeit.default_timer()
print("Head 처리 시간 : %f초" % (terminate_time - start_time))
temp_pd['Main'] = temp_list_main
temp_pd['Head'] = temp_list_head
df2 = df_total.loc[:,['Day']]
new_df = pd.concat([df2, temp_pd], axis = 1)
total_df = pd.concat([total_df,new_df])
total_df.fillna('%s' %(company),inplace=True)
total_df.to_csv("./전처리/2차 전처리(토큰화)/total_df.csv" , mode='w',encoding = 'utf-8-sig')
Python
복사
2. TF-IDF
앞의 과정을 통해서 뉴스 기사들을 단어들로만 이루어진 하나의 문자열로 저장하여 데이터프레임으로 만들었습니다. 이렇게 하나의 문자열로 만든 이유는 바로 TF-IDF를 통해서 새로운 column을 만들기 위해서입니다.
2-1. TF-IDF 정의
TF-IDF의 정의는 다음과 같습니다. (Term Frequency - Inverse Document Frequency)
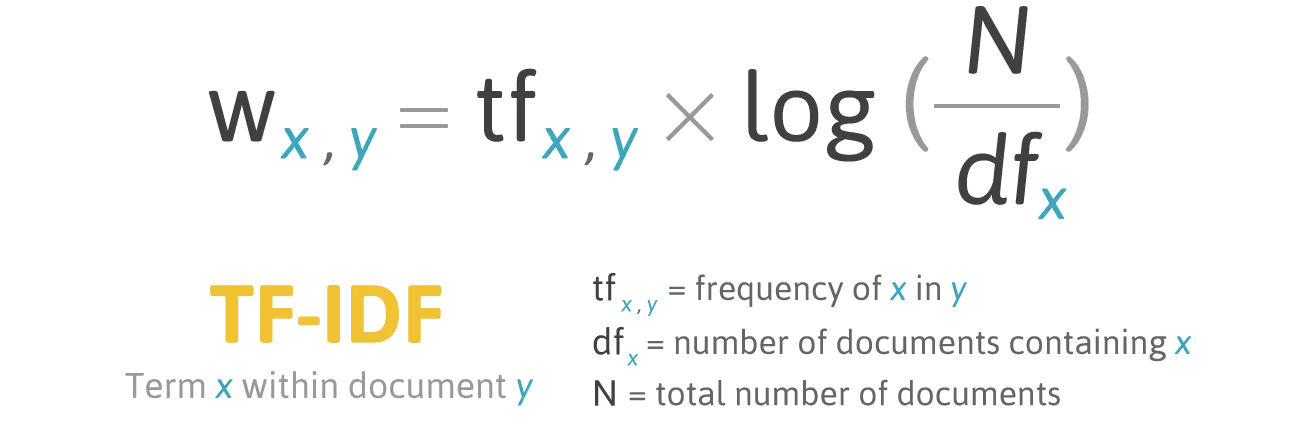
Term Frequency(단어의 빈도)와 Inverse Document Frequency(문서의 빈도의 역)을 곱한 값이 TF-IDF입니다. 각각의 의미에 대해서 생각해 봅시다.
우선, Term Frequency는 특정 단어 x가 등장한 횟수를 특정 문서 y에 등장하는 모든 단어의 수로 나눈 값을 의미합니다. 그리고 Inverse Document Frequency는 전체 문서의 수를 특정 단어 x가 등장하는 문서의 수로 나눈 뒤 로그를 취한 값입니다.
자주 나타나는 단어일수록, 해당 단어는 그 문서를 나타내는 중요한 단어라고 볼 수 있지만, 이 단어가 다른 문서에서도 많이 나타난다면, 사실 그 단어는 어디서나 많이 나타나는 흔한 단어이고, 그 문서의 특징을 반영하기에는 좋은 단어가 아닐 확률이 높습니다.
자주 나타나지만 다른 문서에서도 자주 나타나는 단어에는 작은 가중치를 부여하고, 자주 나타나지만, 특정 문서에서만 자주 나오는 단어에 대해서는 높은 가중치를 부여한다면, 높은 가중치를 가지고 있는 값이 그 문서를 잘 나타내는 단어라고 생각할 수 있습니다.
2-2. TF-IDF 적용
해당 개념을 이용하여 직접 TF와 IDF를 구할 수 있겠지만, 파이썬의 sklearn 라이브러리에는 TF-IDF를 구해주는 TfidfVectorizer가 존재합니다. 이 라이브러리를 이용하여 위에서 구한 데이터들을 TF-IDF 값으로 만들어봅시다.
total_df = pd.read_csv('./전처리/2차 전처리(토큰화)/total_df.csv')
total_df.dropna(axis=0,inplace=True)
# TF-IDF를 이용하기 위한 라이브러리
from sklearn.feature_extraction.text import TfidfVectorizer
list_features =[500,1000,1500,2000]
for i in list_features:
start_time = timeit.default_timer()
text = total_df['Head'].to_list()
# min_df : 최소한의 문서에서 나타나야할 빈도
# max_features : TF-IDF 중 피쳐의 최대 갯수 설정
tfidf_vectorizer = TfidfVectorizer(min_df = 300, max_features = i)
tfidfv = tfidf_vectorizer.fit(text) # 벡터라이저가 단어 학습
final_df = pd.DataFrame(tfidfv.transform(text).toarray(), columns=sorted(tfidf_vectorizer.vocabulary_))
df3 = total_df.loc[:,['Company','Day']].reset_index().drop(['index'],axis=1)
df4 = pd.concat([df3, final_df], axis = 1)
terminate_time = timeit.default_timer()
print("TF-IDF 처리 시간 : %f초" % (terminate_time - start_time))
df4.to_csv("./전처리/TF-IDF/head_tf-idf_%s.csv" %(str(i)) , mode='w',encoding = 'utf-8-sig')
Python
복사
위의 코드를 실행하면 아래와 같은 데이터프레임을 얻을 수 있습니다.
3. 라벨 설정하기
학습에 사용할 피쳐들을 만들었지만, 아직 주가 데이터를 가져오지 않아서 예측할 라벨인 주가 방향을 만들지는 못했습니다. 그래서 주가 데이터를 가져와서 라벨을 만들어보려고 합니다.
3-1. 주식 데이터 전처리하기
주식의 시가 총액 데이터는 https://github.com/FinanceData/marcap에서 가져올 수 있습니다. 아래 과정을 통해서 데이터를 전처리하고 라벨을 만들어 봅시다.
import pandas as pd
mcp = pd.read_csv('./raw/marcap-2019.csv')
# 19년 1월 2일 기준 KOSPI 시가총액 상위 100개
mcp1 = mcp[
(mcp['Date'] == '2019-01-02') &
(mcp['Marcap'][(mcp['Date']=='2019-01-02') & (mcp['Market']=='KOSPI')].rank(ascending=False) <= 100)
]
codes = mcp1['Code'].values # 위의 기준에 맞는 기업들의 code들을 가져온다.
df = mcp[mcp['Code'].isin(list(codes))] # 그리고 그 code와 일치하는 기업만 새로운 df로 만들어준다.
df_stock = df.copy()
# ChangeCode : 기본 라벨값
# 1: 전일대비 상승 1 -> 1
# 2 : 전일대비 하락 2 -> 0으로 변경
# 3 : 등락 변동 없음 3 -> 1로 변경 (라벨 1은 결국 손실이 없는 경우, 라벨 2는 손실이 발생한 경우)
df_stock['ChangeCode'][df_stock['ChangeCode']==2] = 0
df_stock['ChangeCode'][df_stock['ChangeCode']==3] = 1
# 변경된 라벨로 csv로 만들어주자
df_stock1 = df_stock[['Code','Name','ChangeCode','Date']]
df_stock1 = df_stock1.sort_values(by=['Code','Date'])
df_stock1.to_csv('./전처리/df_stock.csv', encoding='utf-8')
Python
복사
3-2. 데이터 분포 확인
코스피 시총 상위 100개의 기업은 기본적으로 데이터의 등락 폭이 크지 않습니다. 예를 들어, 삼성전자가 하루에 0.5% 상승을 했다고 치면, 실제로 상승을 한 것은 맞지만 과연 이 뉴스들이 실제로 저 가격에 영향을 미쳤는가 하고 생각을 해보면, 영향을 미치기보다는 시기 총액이 큰 기업들이 평균적으로 위아래로 움직이는 정도일 뿐이라고 생각할 수 있습니다.
이처럼 큰 상승과 큰 하락이 아니면 전체적인 시장의 흐름에 따라 0을 기준으로 작은 변동만 있을 확률이 높습니다.
아래 코드를 통해서 주가 변화율의 분포도를 확인해 봅시다.
import numpy as np
import matplotlib as mp
import matplotlib.pyplot as plt
mp.rcParams['axes.unicode_minus'] = False # 폰트 깨짐 방지
plt.rcParams["font.family"] = 'Malgun Gothic' # 그래프 폰트
plt.hist(df_stock['ChagesRatio'],range=(-30,30), bins=60, density=True)
plt.xlabel('전일 종가 대비 변화율', size=12)
plt.ylabel('density', size=12)
plt.title('코스피 시가총액 상위 100위 종목 변화율 분포도', size = 10)
plt.show()
Python
복사
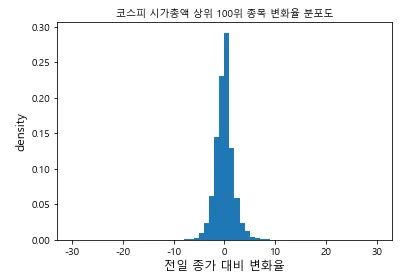
위의 그림을 보면, 대부분의 데이터가 0을 기준으로 모여있고, (대부분의 주가는 이렇게 분포할 수밖에 없습니다) 0을 기준으로 50%가 (-0.98%, +0.91%)에 몰려 있습니다.
그래서 이런 식으로는 제대로 된 학습이 되지 않을 것으로 생각하였습니다. 그래서 다음과 같은 가정을 하였습니다.
1.
모델의 결과에 따라 매일 거래를 한다.
2.
거래마다 수수료가 발생한다.
3.
수수료를 포함한 거래이기 때문에 최소 0.5% 이상의 상승이 있어야지만 손해를 보지 않는다.
그래서 0.5% 이상의 상승이 있어야지 수익이 나고 판단하여 나중에 라벨을 바꿔서 모델링을 진행해 보려고 합니다.
4. 모델링
이번 프로젝트에서는 어떻게 머신러닝 모델을 학습하는지는 다루지 않습니다. 그렇기 때문에 PyCaret을 이용하여 모델링을 진행하지만, 최종적으로 어떤 관점으로 라벨을 설정하고 진행하는지에 포커스를 두면 좋을 것 같습니다.
4-1. 최종 전처리
실제 학습할 데이터와 그에 해당하는 주식 label 값을 구했으니, 실제 학습을 진행해 보려고 합니다. 현재 특정 날짜의 기사 데이터와 특정 날짜의 라벨이 존재합니다.
1월 2일 뉴스를 토대로 1월 2일의 주가의 방향을 예측하는 것은 사실 말이 안 됩니다. 1월 2일 뉴스를 토대로 다음 날의 주가 방향을 예측하는 것이 맞는 방향이기 때문에 다음과 같이 특정 날짜의 라벨 데이터와 그 전날의 뉴스 데이터를 매칭시켜야 합니다.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df= pd.read_csv("./전처리/df_stock.csv")
df_stock = df.drop(['Unnamed: 0','Code'],axis = 1)
# 1월3일의 결과를 1월 2일의 기사를 토대로 예측해야 하므로 한칸 위로
df_stock['target']=df_stock['ChangeCode'].shift(-1)
# shift가 발생하면서 1월2일의 라벨들이 12월 30이롤 이동하기 때문에 삭제
check = (df_stock['Date'] == '2019-12-30')
# ~ 기호를 이용하여, 해당하지 않은 데이터만 남긴다
df_stock = df_stock[~check]
# 라벨인코딩을 통해서, 해당 타겟 값을 바꿔준다.
encoder = LabelEncoder()
encoder.fit(df_stock['target'])
labels = encoder.transform(df_stock['target'])
df_stock['target'] = labels
Python
복사
4-2. PyCaret
학습할 데이터 셋을 완성했으니, 실제로 학습을 해보려고 하는데, 분류에 대한 머신러닝 종류도 엄청나게 많이 있습니다. 랜덤 포레스트부터 시작해서 로지스틱 회귀 등등…. 아주 다양한 분류 모델이 있는데, 각각의 모델의 장단점을 이해하면서 일일이 적용하기에는 많은 시간이 소모되기 때문에 PyCaret을 이용해서, 다양한 모델들을 한 번에 학습하려고 합니다.
AutoML(Automated Machine Learning)은 머신러닝 모델 개발의 전체 과정을 자동화하여, 데이터 전처리, 모델 선택, 하이퍼파라미터 튜닝, 모델 평가 등 복잡한 과정을 효율적으로 수행하는 기술인데, PyCaret도 AutoML 오픈 소스 라이브러리 중 하나입니다.
간단하게 말해서, 우리가 분류를 목적으로 하면, 분류에 해당하는 모델들을 다 불러와서, 직접 학습할 데이터와 라벨만 정해주면 최적의 파라미터에 맞게 학습을 해서 정확도를 여러가지 지표를 알려주는 라이브러리 입니다.
심지어 특정 모델들에 맞춰서 파라미터까지 일일이 학습을 하면서 최적의 파라미터와 앙상블을 통해서 여러 모델을 합친 결과까지 알려줍니다.
(이렇게 들으면 만능 같지만, 어떻게 보면 각각의 요소들이 의미하는 바를 이해하지 못한 채 의존하게 될 수도 있으니, 양날의 검이라고 생각합니다)
본론으로 돌아와서, 일단 pycaret을 이용해서 학습을 진행해 봅시다.
from pycaret.classification import *
# main - feature 500
df_news = pd.read_csv('./전처리/TF-IDF/main_tf-idf_500.csv')
# 주식 데이터와 뉴스 데이터를 맞추기 위해서,
# 회사의 이름과 날짜를 하나의 id(키) 역할로 만듬
df_stock['Date'] = df_stock['Date'].str.replace('-','.')
df_stock['id'] = df_stock['Name']+df_stock['Date']
df_news['id'] = df_news['Company']+df_news['Day']
total_df = pd.merge(df_stock, df_news, on = 'id').drop(['Name','Date','id','Company','Day','Unnamed: 0','ChangeCode'],axis=1)
total_df = total_df.dropna()
#### pycaret 사용 ####
setup_clf = setup(data=total_df, target='target', session_id = 1, use_gpu = True)
top5_main_500 = compare_models(sort='Accuracy', n_select=5, exclude=['catboost','gbc']) # 해당 모델들이 시간이 너무 걸려서 그냥 빼버림 ㅠㅠ
Python
복사
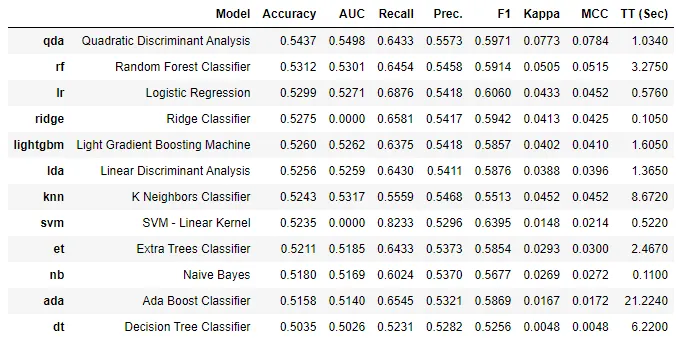
실행한 결과 위의 그림처럼 각각의 모델별로 평가 지표와 함께 출력됩니다.
4-3. 라벨 기준 변경
하지만 정확도가 0.54인 걸 보면, 단순하게 주식이 0퍼 이상 상승할 것이다, 하락할 것이다를 맞추기에는 힘들 것 같습니다. 그래서 3-2. 데이터 분포 확인 여기서 언급했던 것 처럼, 라벨을 설정하는 기준을 변경해보려고 합니다.
그래서 이전 글에서 언급했듯이, 해당 타겟을 나눠서 생각해 봅시다.
1번 케이스 : (+0%를 기준으로 미만이면 0(손실), 이상이면 1(이익))
2번 케이스 : (+0.5%를 기준으로 미만이면 0(손실), 이상이면 1(이익))
3번 케이스 : (+1%를 기준으로 미만면 0(손실), 이상이면 1(이익))
아래 결과의 기준은 뉴스의 제목이 아닌, 본문의 내용을 토대로 TF-IDF로 만든 500개의 피쳐로만 학습을 진행하였습니다.
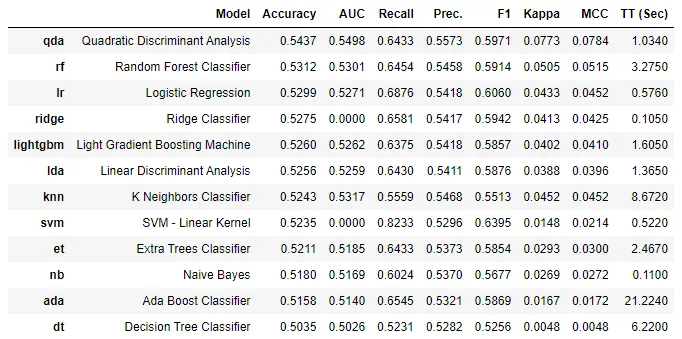
1.
Case 1
2.
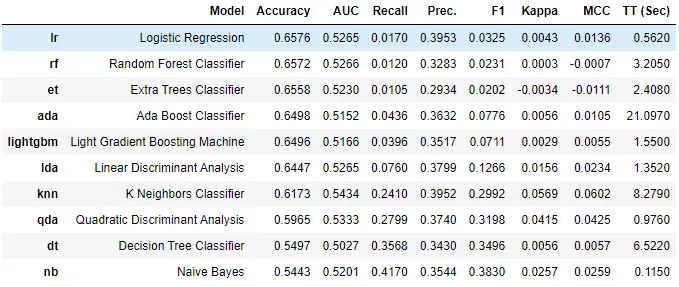
Case 2
3.
Case 3
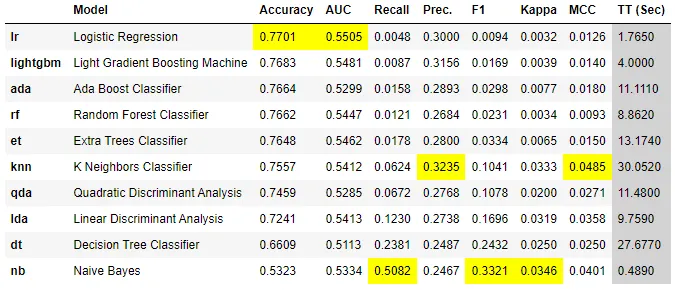
기본적으로 머신러닝의 성능을 평가할 때, 정확도를 제일 먼저 확인합니다. 처음에 케이스를 나눠서 머신러닝을 진행하니 최고 성능 모델을 기준으로 정확도가 비약적으로 상승하였습니다.
Case 1 0.5437 -> Case 2 : 0.6576 -> Case 3 : 0.7701
단순히 학습을 하면서 기계에 조금 더 명확한 기준을 줬기 때문에 정확도가 상승했다고 생각을 할 수도 있지만, 모델을 평가할 때는 단순히 정확도로만 성능을 평가할 수 없습니다.
정확도는 말 그대로 얼마나 맞췄는지를 보기 때문에, 수익이 발생한다는 지표(1)과 수익이 발생하지 않는다는 지표(0)들을 구분하지 않고 그냥 맞추는 것이 중요합니다. 이러한 정확도로만 예측하는 것은 매우 큰 문제를 가진 모델로 남을 수도 있습니다.
5. 평가 지표
모델을 평가하는 성능지표는 다양합니다. 일반적으로 정확도를 많이 확인하지만, 정확도가 무조건 높아야지만 좋다는 생각은 문제를 발생시킬 수 있습니다. 그래서 정확도 외의 다른 평가 지표를 알아봅시다.
5-1. 오차 행렬
오차 행렬은 예측 오류가 얼마인지 와 어떤 유형의 예측 오류가 발생하는지 알려주는 지표입니다.
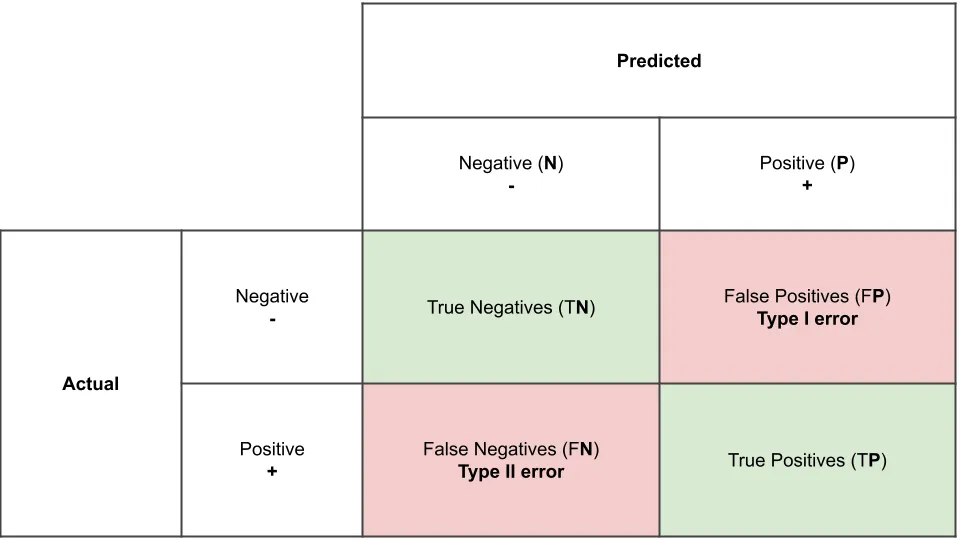
이진 분류의 경우, negative(0)와 positive(1)로 나눌 수 있습니다. 그리고 실제 값과 모델이 예측한 값에 따라서 아래 4가지 경우로 나눌 수 있습니다.
TN은 예측값을 negative(0)로 예측했고, 실제로도 negative(0)인 경우
FP는 예측값을 positive(1)로 예측했는데, 실제 값은 negative(0)인 경우
FN은 예측값을 negative(0)로 예측했는데, 실제 값은 positive(1)인 경우
TP는 예측값을 positive(1)로 예측했는데, 실제 값은 positive(1)인 경우
이렇게 4가지를 오차 행렬로 나타낼 수 있습니다. 그냥 맞게 예측하는 것(TN, TP)만 중요한 게 아니냐고 할 수 있는데, 이것은 1차원적인 해석입니다.
5-2. 정밀도와 재현율
암 환자를 예측하는 모델이 있다고 가정해 봅시다.
실제 암 환자(positive)를 암 환자가 아니(negative)라고 예측했다고 생각해 봅시다(FN). 이런 경우, 환자는 암이 있지만 잘못된 모델에 의해서 목숨을 잃을 수도 있습니다.
하지만, 반대의 경우 실제로 암 환자가 아닌데(negative), 암 환자(positive)라고 예측을 했다고 생각해 보자(FP). 이런 경우에는 환자가 재검사를 통해서 다시 암 환자가 아니라고 밝혀질 가능성이 높고, 비용만 추가될 뿐 실제로 목숨과는 관계가 없습니다.
이번에는 위의 사례와 반대로 스팸메일 여부를 판단하는 모델이 있다고 가정해 봅시다.
실제 스팸 메일(positive)을 일반 메일(negative)로 예측하여도(FN), 실제 사용자가 느끼는 불편함은 크지 않습니다. 하지만 반대의 경우인 일반 메일(negative)을 스팸 메일(positive)로 예측한다면(FP), 꼭 필요한 메일도 스팸메일로 분류되어 업무에 지장이 있을 가능성이 높아집니다.
이처럼 단순하게 정확도만 고 예측을 잘했냐를 따질 것이 아니라, 각각의 상황에 맞게 오차 행렬을 통해서 정확도를 포함한 다른 지표들도 참고해야 합니다.
1.
정확도(accuracy) = (TN+TP) / (TN + FP + FN + TP)
2.
정밀도(precision) = TP / (FP + TP)
3.
재현율(recall) = TP / (FN + TP)
정확도는 말 그대로 예측이 얼마나 성공했냐만 따지기 때문에, 암 환자의 경우, FN의 비율이 중요하므로 재현율 지표가 더 중요해지고 스팸 메일의 경우, FP의 비율이 중요하므로 정밀도 지표가 더 중요하다고 생각할 수 있습니다.
그리고 위와 같은 특별한 경우에서는 특정 지표가 더 중요하게 생각되는 것은 맞지만, 그렇다고 반대되는 쪽의 비율도 무시할 수는 없습니다. (암 예측 모델의 경우, 평범한 사람이지만 암 환자로 지속적으로 판정이 난다면 그 병원은 얼마 안가 망할 것이다...)
그래서 정밀도와 재현율의 적절하게 조합된 새로운 평가 지표가 필요합니다.
5-3. F1 Score
F1 Score는 이러한 상황을 해결하기 위해서 나온 지표로, 정밀도와 재현율을 조화평균으로 계산한 지표입니다. 정밀도와 재현율이 극단적인 차이가 날수록 이 지표는 낮아집니다.

그럼 모델의 성능을 평가하기 위한 지표에 대해서 대략적으로 알아보았으니, 다시 현재 프로젝트로 돌아와서 정확도가 아닌 다른 평가 지표도 확인해 봅시다.
CASE 1
(0% 기준) | 예측 | ||
N(0) | P(1) | ||
실제 | N(0) | 1108 | 2042 |
P(1) | 1077 | 2407 | |
정확도 | 정밀도 | 재현율 | f1 |
0.530 | 0.541 | 0.691 | 0.607 |
CASE 2
(+0.5% 기준) | 예측 | ||
N(0) | P(1) | ||
실제 | N(0) | 4218 | 145 |
P(1) | 2200 | 71 | |
정확도 | 정밀도 | 재현율 | f1 |
0.647 | 0.329 | 0.031 | 0.057 |
CASE 3
(+1% 기준) | 예측 | ||
N(0) | P(1) | ||
실제 | N(0) | 5099 | 5 |
P(1) | 1528 | 2 | |
정확도 | 정밀도 | 재현율 | f1 |
0.769 | 0.286 | 0.001 | 0.003 |
정확도라는 지표를 제외하고, 다른 지표들을 보기 시작하니, 수익이 나는 기준을 올릴수록, 정확도는 올라가지만, 그 외의 평가 지표가 떨어지기 시작합니다.
그렇다면 주식 투자의 입장에서 어떤 지표가 중요한지 생각해 봅시다.
실제로는 수익이 나지 않았을 때(negative), 번다고 예측한다면(positive), 이는 돈을 움직이는 입장에서 엄청난 큰 손해로 올 것이다. 투자하지 않은 것보다 더 큰 손해를 불러오기 때문에, 우리는 재현율보다는 정밀도가 더 중요한 지표라고 생각을 할 수 있다.
(물론, 수익을 낼 기회를 최대한 놓치지 않으려면 재현율이 중요할 수도 있지만, 모든 투자의 기본은 안전한 투자니….)
Case 3의 경우, 수익이 난다(positive)는 것으로 예측하는 경우가 훨씬 적기 때문에 모델 자체의 문제가 있어서 정밀도가 생각보다 높게 나오지만, 사실은 저 값 자체도 문제가 있다고 볼 수 있습니다.
정리하자면, 수익이 나는 기준점을 변경하면서 실제 모델에서의 라벨 데이터들의 비율에서 0(negative)의 비율이 더 높아지니, 모델들이 그냥 0(negative)에 대해서만 더 많은 학습을 진행해서, 실제 예측도 0으로 예측하는 경우도 많아지게 됩니다. 이러한 부분을 어떻게 해결할 수 있을까요?
6. 임곗값
Case 3번의 경우, 정확도는 높지만 다른 지표가 엉망인 것을 확인하였습니다. 그렇다면 조금이라도 다른 지표를 올릴 방법은 없을까요?
6-1. 예측 확률 분포 확인
먼저 대부분의 값을 0으로 예측하는 상황에서 실제 0과 1을 예측하는 확률의 분포를 확인해봅시다.
import numpy as np
pred_proba = lr_clf.predict_proba(X_test) # 각 결과의 대한 예측 확률
pred = lr_clf.predict(X_test)
pred_proba_result = np.concatenate([pred_proba, pred.reshape(-1,1)], axis = 1)
df_proba = pd.DataFrame(pred_proba_result)
Python
복사
predict_proba()를 이용하여 각각의 지표에 대한 예측 확률을 확인할 수 있습니다. 대부분 0을 예측하는 것 같은데, 시각화를 통해 어떻게 분포되어있는지 알아봅시다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = [10, 6]
%matplotlib inline
fig, ax = plt.subplots()
ax.boxplot([df_proba[0], df_proba[1]], sym="b*")
plt.xticks([1, 2])
plt.show()
Python
복사
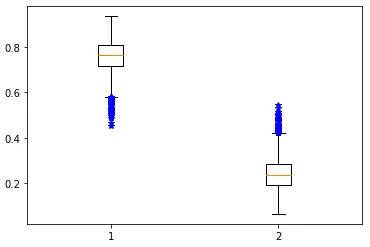
역시 대부분이 0.7에서 0.8 사이의 확률로 0을 예측한다는 것을 알 수 있습니다. 이번에는 0을 예측하는 확률의 분포를 히스토그램으로 확인해보겠습니다.
# 0을 예측하는 확률의 분포
plt.hist(df_proba[0], bins=100, density=True, alpha=0.7, histtype='stepfilled')
plt.show
Python
복사
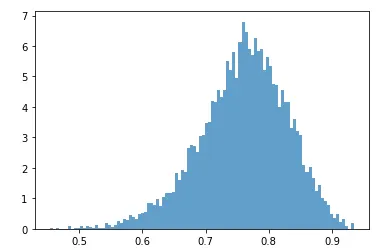
현재 예측 확률의 임곗값은 0.5로 거의 모든 데이터들이(7개를 제외한) 다 50%가 넘는 확률로 0을 예측하고 있습니다. 이러한 상황에서 이러한 임곗값을 조절하여 조금 더 0과 1의 예측하는 비율의 분포를 바꿔보면 어떨까요?
6-2. 임곗값 조정
sklearn에서는 Binarizer를 통해서 지정한 임곗값(threshold)보다 높으면 1 낮으면 0을 반환해 줍니다. 이를 통해서 0과 1을 예측하는 기준점을 변경하여 머신러닝 지표가 어떤 식으로 변화하는지 알아봅시다.
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred):
print("오차 행렬\n", confusion_matrix(y_test, pred))
print("정확도 : ", accuracy_score(y_test, pred))
print("정밀도 : ", precision_score(y_test, pred))
print("재현율 : ", recall_score(y_test, pred))
print("f1 : ", f1_score(y_test,pred))
print("roc : ", roc_auc_score(y_test,pred))
from sklearn.preprocessing import Binarizer
thresholds = [0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55]
def get_eval_by_threshold(y_test, pred_proba, thresholds):
for custom in thresholds:
binarizer = Binarizer(threshold=custom).fit(pred_proba)
custom_predict = binarizer.transform(pred_proba)
print(f"임곗값 : {custom}")
get_clf_eval(y_test, custom_predict)
get_eval_by_threshold(y_test, pred_proba[:,1].reshape(-1,1), thresholds)
Python
복사
CASE 1
(임곗값 0.25) | 예측 | ||
N(0) | P(1) | ||
실제 | N(0) | 3036 | 2068 |
P(1) | 854 | 676 | |
정확도 | 정밀도 | 재현율 | f1 |
0.560 | 0.246 | 0.442 | 0.316 |
CASE 2
(임곗값 0.3) | 예측 | ||
N(0) | P(1) | ||
실제 | N(0) | 4183 | 921 |
P(1) | 1231 | 299 | |
정확도 | 정밀도 | 재현율 | f1 |
0.676 | 0.245 | 0.195 | 0.217 |
CASE 3
(임곗값 0.35) | 예측 | ||
N(0) | P(1) | ||
실제 | N(0) | 4778 | 326 |
P(1) | 1425 | 105 | |
정확도 | 정밀도 | 재현율 | f1 |
0.736 | 0.243 | 0.07 | 0.107 |
임곗값을 변경하면서 지표를 살펴보니, 확실히 임곗값이 0.3을 기준으로 큰 변화가 일어나는 것을 알 수 있습다. 임곗값을 낮추니 정확도를 제외한 전체적인 지표는 상승하였으나, 조금 더 세분화해서 정밀도와 재현율을 더 끌어올려 봅시다.
sklearn에서는 위의 예제와 유사한 precision_reall_curve를 제공합니다. 그래서 이번에는 precision_reall_curve를 이용해서 알아봅시다.
precision_recall_curve의 인자로 실제 데이터 세트와 레이블 값이 1일 때의 예측 확률을 입력하면, 0.11~0.95 정도의 임곗값을 담은 ndarray와 이에 해당하는 정밀도와 재현율을 담은 ndarray를 반환합니다. 이 데이터를 이용해서 그래프를 그려봅시다.
from sklearn.metrics import precision_recall_curve
def precision_recall_curve_plot(y_test, pred_proba):
precisions, recalls, thresholds = precision_recall_curve(y_test, pred_proba)
plt.figure(figsize = (8,6))
# x축 범위 설정
threshold_boundary = thresholds.shape[0]
#정밀도와 재현율 시각화
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label = 'precision')
plt.plot(thresholds, recalls[0:threshold_boundary], label='recall')
start,end =plt.xlim()
# x축 설정
plt.xticks(np.round(np.arange(start,end,0.1),2))
plt.xlabel('Threshold value');
plt.ylabel('precision and Recall value')
plt.legend();
plt.grid()
plt.show()
precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:,1])
Python
복사
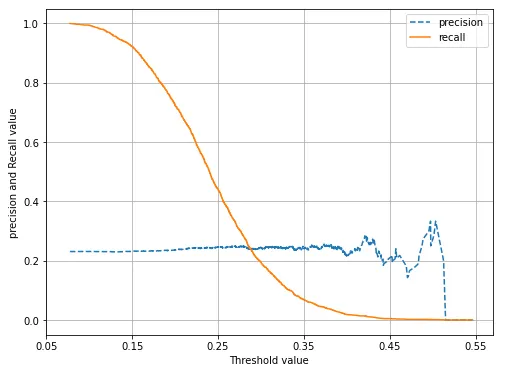
역시 임곗값이 라벨의 비율과 거의 일치하는 시점까지 재현율과 정밀도가 적당한 수준이고, 그 외에는 의미 있는 모델이라고 볼 수 없을 것 같습니다.
7. 마무리
결과적으로 이 프로젝트를 통해서 만든 모델은 거의 의미가 없는 모델이라는 것을 알 수 있습니다. 실질적으로 0% 기준으로 가격의 상승과 하락을 바라보았을 때는, 정확도가 0.53 수준이어서 실질적인 수익을 기대하기 어렵고, 다른 기준의 모델은 정밀도와 재현율을 올리려고 해도, 대부분 수익을 내지 못한다고 예측을 하기 때문에 거의 의미가 없다고 볼 수 있습니다.
해당 논문에도 나오지만, 실질적으로 불균형한 데이터가 정확도가 높아서 선택될 수도 있고, 실질적으로 주가를 예측하는 모델들의 정확도가 50~70% 수준으로 볼 수 있습니다. 이처럼 다른 주식 지표를 제외한, 뉴스 데이터의 특정 단어를 토대로 주가를 예측하는 것은 거의 의미가 없는 모델을 만드는 것과 같다고 볼 수 있습니다.
7-1. Feature Importance
그래도 해당 모델들의 feature importance를 구하면 나름 의미 있는 결과를 볼 수 있었습니다. eli5에서 제공하는 PermutationImportance를 통해서 해당 모델에서 어떤 feature가 중요한지 파악할 수 있습니다.
Permutation Importance란 간단하게 말해서, 특정 피처들을 제거해서 모델을 다시 예측을 하였을 때, 모델의 성능이 떨어진다면, 해당 피처들은 중요한 피처일 것이고 해당 피처를 제거해도 성능의 차이가 없다면 그 피처들은 영향이 없는 피처라고 생각하는 방식입니다.
import eli5
from eli5.sklearn import PermutationImportance
perm1 = PermutationImportance(lr_clf, scoring = "f1", random_state = 42).fit(X_test, y_test)
eli5.show_weights(perm1, top = 80, feature_names = X_test.columns.tolist())
Python
복사
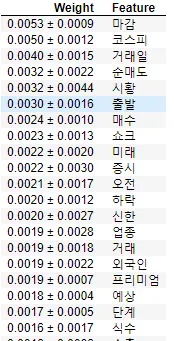
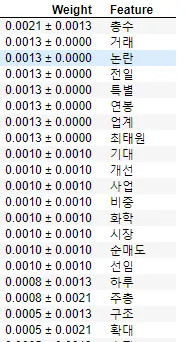
왼쪽은 0% 기준 / 오른쪽은 1% 기준으로 나눈 경우
실제로 Permutation Importance를 통해서 의미 있는 피처가 무엇이 있을까를 알아보면, 다음과 같이 구할 수 있습니다. 생각보다 실제로 가격에 영향을 끼칠만한 키워드들이 있는 것을 볼 수 있습니다.
0% 기준에서는 순매도, 매수, 하락, 외국인과 같은 실제 주식과 관련된 키워드들이 많이 나타나고, 특히 쇼크와 같은 실제로 부정적인 영향을 줄 수 있는 키워드도 볼 수 있다.
1% 기준에서는 기대, 개선, 확대와 같은 가격에 긍정적인 영향을 주는 키워드도 볼 수 있다.
이를 통해서 알 수 있는 것은 결국 컴퓨터는 각각의 단어의 진짜 의미를 알지 못하고 단순한 기계학습을 통해서 해당 단어들이 조금 더 가격에 영향을 미친다고 생각을 합니다.
7-2.개선 방향향
그렇다면 우리가 앞에서 구현하였던 불용어 사전을 통해서, 학습 후 이러한 피처 중요도를 계속해서 분석을 하면서, 실제로 영향이 없을 것 같은 단어를 불용어 사전에 계속해서 추가하고 지속적으로 학습을 할 수 있습니다.
예를 들면, 위에서 최태원(SK 회장)은 가격에 긍정적인 영향을 줄지 부정적인 영향을 줄지 알 수 없고, 단순히 코스피, 마감, 증시와 같은 주식의 방향성과는 관계가 없는 주식 용어들도 영향을 거의 주지 않는다라고 생각할 수 있습니다.
이러한 단어들을 지속적으로 파악하면서 계속해서 불용어 사전을 관리해 나간다면, 성능이 올라가고 해석을 더 잘할 수 있는 모델을 만들 수 있습니다.
7-3. 진짜 마무리
이번 프로젝트는 뉴스 기사와 주가가 나름의 상관관계가 조금은 있지 않을까로 시작하였지만, 역시 이미 예측할 만한 데이터들이 아닌 정말 뜬금없는 수많은 단어들 사이에서 학습을 진행하니 의미 있는 모델이 나오지 않았습니다. 하지만 이러한 접근법을 통해서 더 나아질 방향을 알 수 있게 되었고, 각각의 지표가 의미하는 바가 무엇인지 조금 더 이해할 수 있었습니다.
추가적으로 이러한 부분과 실제 주식에서 사용되는 다양한 보조 지표를 추가로 학습을 한다면, 조금 더 의미 있는 모델까지 완성할 수 있을 것으로 보입니다.